Feature Extraction - Extract data from raw logs
Overview
Feature Extraction allows processing of unstructured logs and enhances it by adding metadata extracted from the log. Using simple queries, search for specific information and store them in different variables that can then be used in dashboards and log search.
This is especially useful in cases where required data is not part of a structured key:value pair and instead the data is part of a message or any log line. Multiple Feature Extraction operations can be setup and run in parallel on various types of logs.
Setting up & Viewing Feature Extractions
The scope is limited to the logs of the application under which the Feature Extraction is created. Once setup, all ingested logs for that application are processed at ingest based on the specific rules provided.
Feature Extraction works on logs ingested post setting up the rule.
Feature Extraction is available under the Logs dropdown in all application homepages.
Under Feature Extraction, there are two tabs Data View and Operations
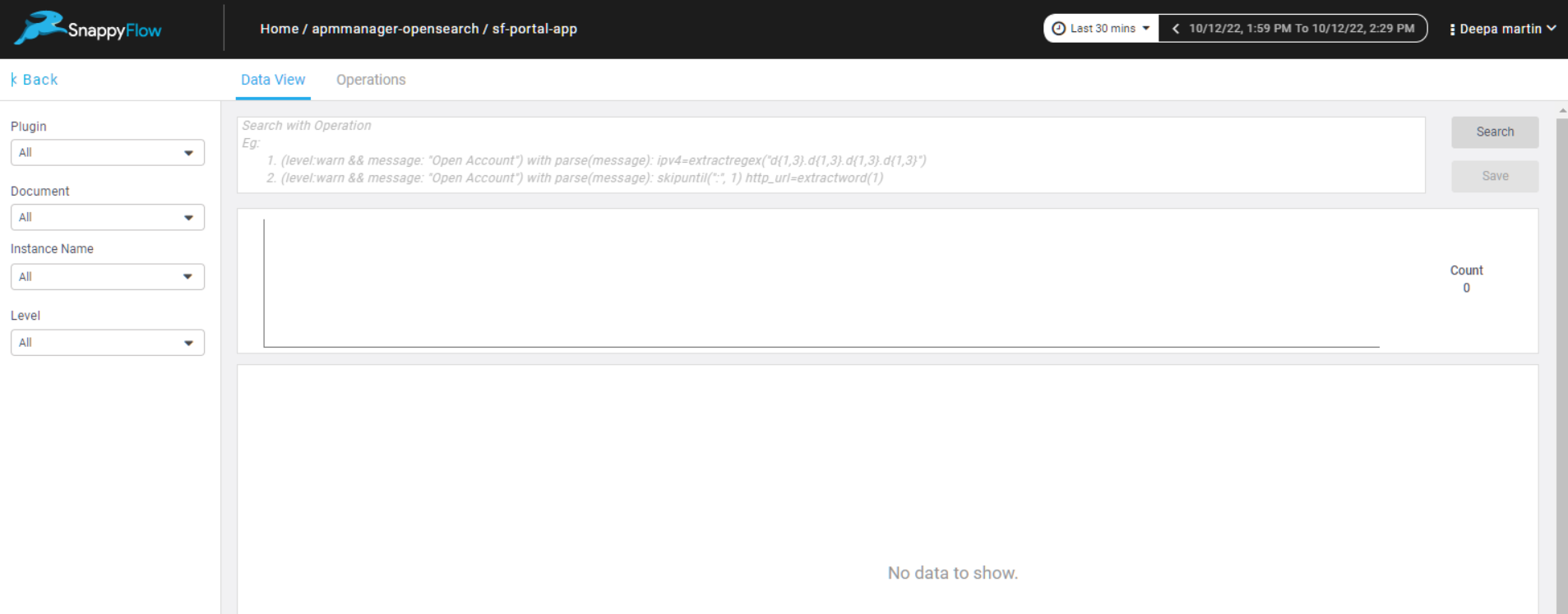
Data View Tab
The Data View tab shows all the logs ingested for the respective application. Using the Filters and Feature Extraction query, target information can be searched. To create a new Feature Extraction query, type in the query in the search box and hit Search. Only for successful search operations, save button will be activated. All saved queries can be found in the Operations tab.
Operations Tab
The Operations View tab lists all the Feature Extraction operations that have been saved and their current status.
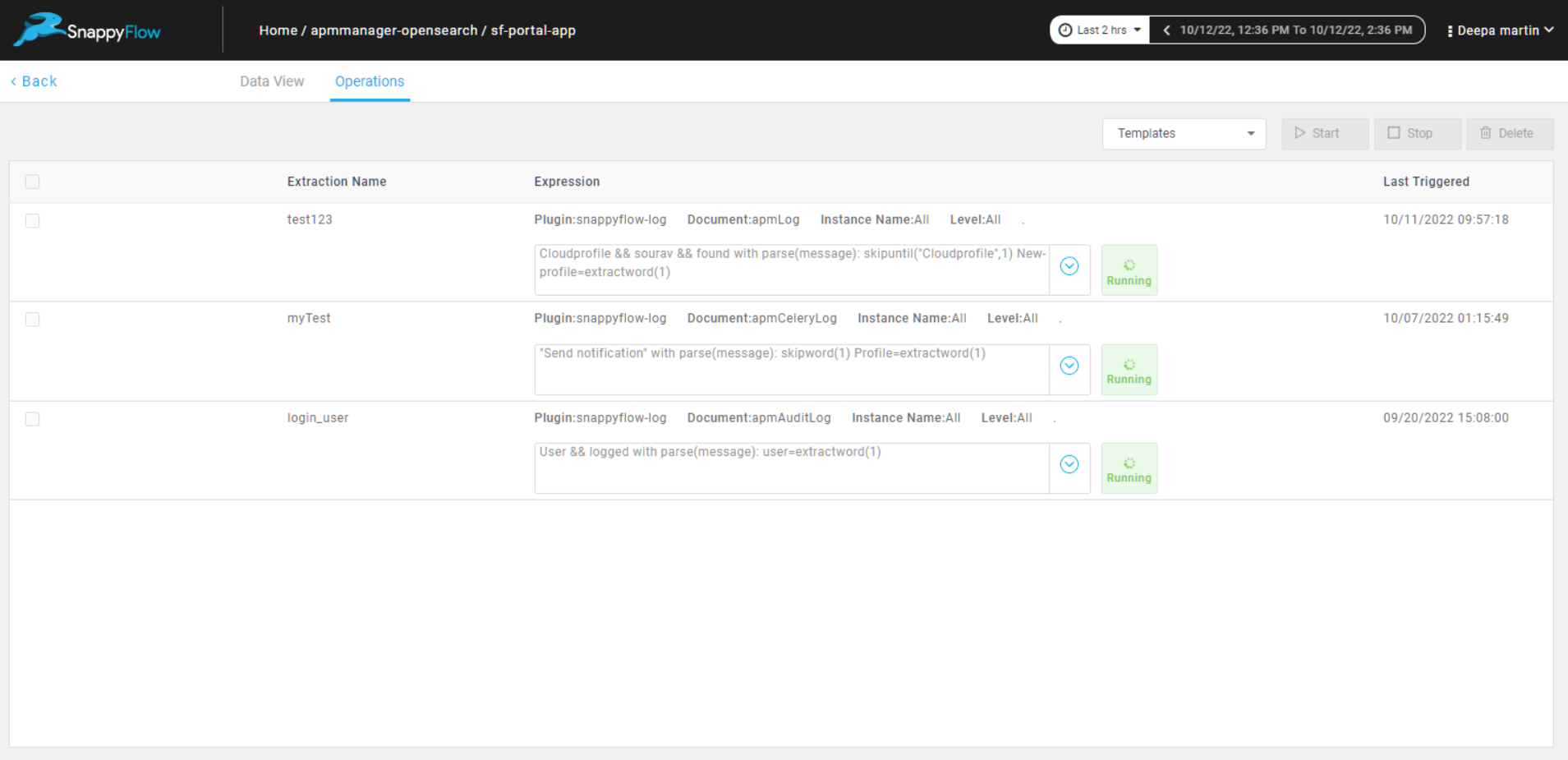
How it works
Feature Extraction is useful in parsing unstructured logs. Using a combination of built-in filters, search strings, skip and extract functions, specific information can be extracted from complex log lines.
Imagine a cursor or pointer at the beginning of a log line. This cursor can be moved along the log line from left to right to reach a particular position of interest. This is called skipping. The character/word that immediately follows the cursor is processed based on the query provided. This is called extracting.
The scope of Feature Extraction Rules are limited to the application under which the rule is created.
Step1: Search for logs using the built-in filters
In the Feature Extraction page, filter logs based on Plugin type, Document type, Instance name and log level.

Step 2: Create a Feature Extraction rule
A Feature Extraction rule comprises of 3 key parts as in the below example

Search String
This is a search string and is used to filter logs using simple search strings. It is a single or a combination of strings. Use double quotes ("") to search for a specific pattern of strings.
Examples
new user - This will search for both the strings irrespective of their position.
"new user" - This will search specifically for the string new user
"new user" "create account" - This will search for two separate patterns new user and create account
new user "create account" - Here only create account is a pattern.
Field to be parsed
is the name of the field in the log whose content is to be parsed. The contents of
field_nameare parsed character by character from left to right based on the command that follows.Command
It comprises of single or multiple functions which are executed one by one, on the contents of
field_name. The function can either be a skip or an extract function.
Step 3: Save Feature Extraction rule
Use the search bar in the Data View tab to enter the Feature Extraction rule and hit Search. If a Feature Extraction rule is valid you will see filtered logs matching your search and the Save button will be activated and lets you save the rule. This rule will now run on all incoming logs that match the filter criteria for the application under which the rule is created. Saved feature extractions can be found in the operations tab.
Feature Extraction Functions
There are two type of functions - Skip and Extract.